Model comparison is an easy story: GPT versus Claude, the new model versus the old one, who won this week's benchmark.
But in practical agent work that is often the wrong first question.
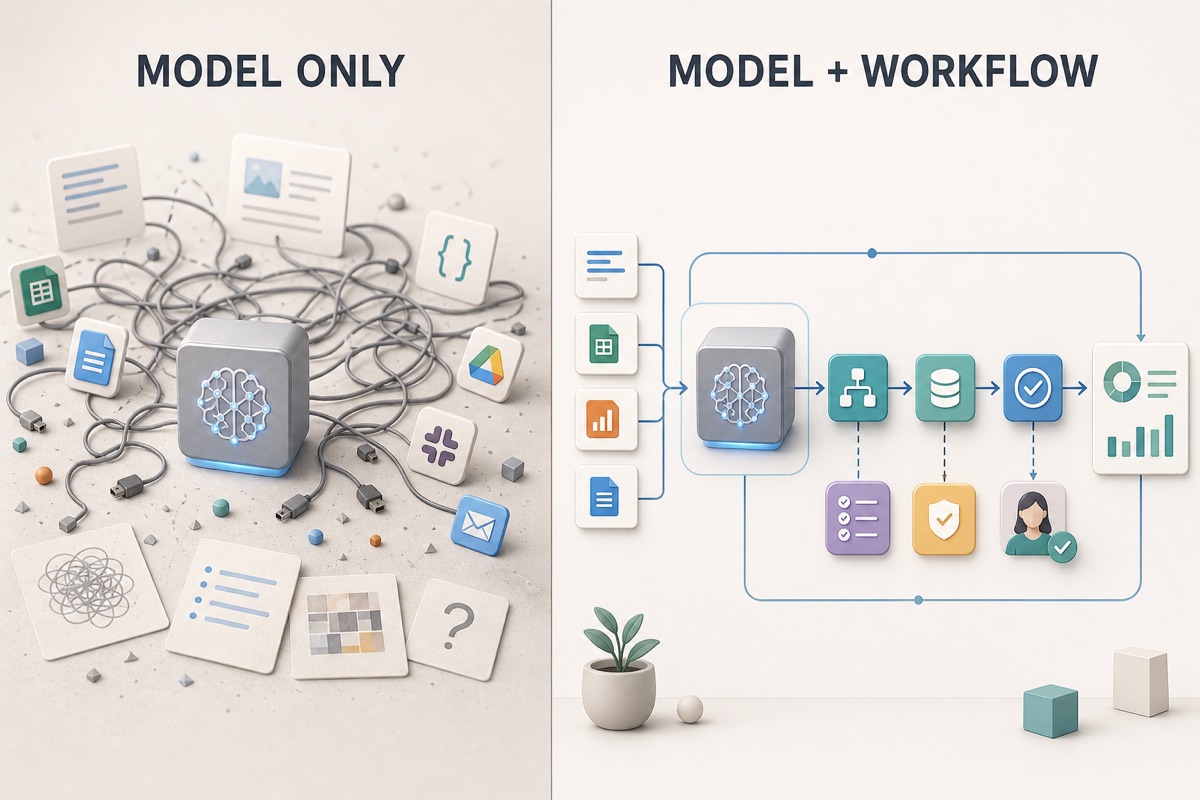
The same model can look clumsy in one environment and very useful in another. Not because the model changed, but because the workflow around it changed.
A weak instruction is: "Follow competitors and make us a report." It sounds reasonable, but for an agent it is fog. Which competitors? Which sources? How often? What changes matter? What is a good report? When should a human react?
A better instruction defines the list, sources, cadence, output format and escalation criteria. For example: follow these 12 competitors weekly, check their sites, LinkedIn posts, news, launches, pricing changes and open jobs, and deliver a Monday-morning summary of what changed, why it matters and whether we need to act.
The difference is not the model. The difference is the definition of the work.
Agent quality is often created by simple but unglamorous decisions: what task it has, which sources it uses, what changes it looks for, what output it returns and when a finding becomes a decision for a human.
If an agent fails, the first conclusion should not always be "the model is bad". A better question is whether the work was defined clearly enough for the agent to have a chance.